ETL Diaries: in-house Data Framework
ETL stands for Extract-Transform-Load. Often companies need to load data either from their products or third parties into their databases. This process is precisely what ETL is designed for.
The idea is incredibly simple: extract data from a source, transform it accordingly and load into a database (or, as in ELT, the data is loaded first and later transformed). However, even simple ideas can become very complicated.
A very dire landscape
Just a few days after I joined the team in one of my previous roles, I had to investigate and solve a few bugs in our data pipelines. Apparently the data in a few tables was not up to date, and a few reports depended on it. At first, it sounded like a simple problem.
As I started to dig, I found out that some of these tables were outdated by 3 to 6 months. At this point, one might wonder how no one noticed. After asking around, a co-worker mentioned that the current ETL scripts are being executed in an EC2 instance in AWS. Logs? The only available logs were from the last execution — and only stored in said EC2 instance.
While the code was at least in a repository in... BitBucket... the deployments were also manually done by copying the files via scp. So, the idea was to fix the code, get a review, merge into main, manually copy the files and check the schedule in the cronjob. Additionally, double-check the secrets that were manually added as environment variables.
The setup was error-prone and only worked in a limited capacity. And, not surprisingly, applying fixes would take longer.

Even though this was not fun at all, there was a lot of opportunity to improve things. The slightly challenging part was to convince management that something had to change.

Solutions?
Just because ETLs are simple, that doesn't mean it's simply a matter of executing a script somewhere. It can become very complicated very fast. How to find the necessary logs to solve a problem? How to easily rerun failed processes? How to guarantee idempotency? How to load big data sets? How to partition the data? How to get an alert in case something fails? The list goes on and on...
It is not a surprise that there are a few companies specialized in ETL, such as Stitch and AirByte. Alternatively, there are also Singer taps (all open source). The taps, however, are often outdated and the striking lack of maintenance causes more headaches than solution.
The problem we had with third party solutions was that they were often limited in a few aspects. Observability, for example, was not something they easily provided out of the box. Support in case of failures was often not efficient. Additionally, any customization our business would require was simply off the table.
These experiences are from several years ago; current third-party solutions may have improved since then.
To us, then, the solution had to come from within the company.
In house solution
After weeks of evaluations and debates, management decided that at first a third party would be used for ETLs. However, integrations that were not supported by them or that require custom code, would be developed in-house — and there were a considerable number of them. A proper evaluation on how best to handle those was not a priority.
I started developing the solution on the side - the Data Framework. A framework that would handle everything (or almost) ETL related. It would:
- simplify the development of custom-made integrations
- contain libraries for everything:
- Configuration and logging
- Database connections
- Metrics and alerting
- Secret handling
- Network tooling
- define standard inputs, to facilitate idempotency
This is how it looked like:
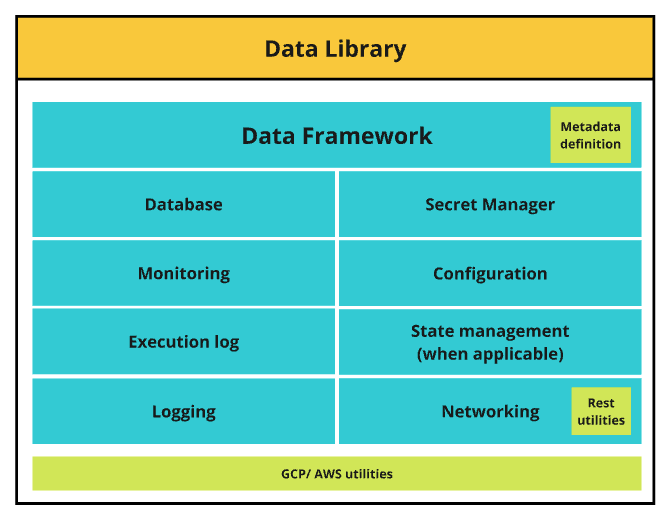
All the different modules were under a library - the Data Library. Each module can be used separately if desired. The idea, though, was for an ETL to create a class that inherits from Data Framework, which will orchestrate the execution and usage of all other different modules. Roughly, this is how the Framework class looks like:
1import configuration as config
2
3class DataFramework:
4 def __init__(self) -> None:
5 load_configuration_from_file()
6 create_metrics()
7
8 job_id = uuid.uuid4()
9
10 def run(self) -> None:
11 start_time = int(time.time())
12 try:
13 self.main()
14
15 records_loaded = self.metric_records_loaded()
16 records_saved = self.metric_records_saved()
17 records_failed = self.metric_records_failed()
18 except Exception as e:
19 logging.error(e)
20 raise e
21 finally:
22 end_time = int(time.time())
23 observe_execution_time(end_time - start_time)
There are many more details to it, but the above implementation covers how it used to function. That is:
- On the
__init__method, load configuration, create metrics and assign a job id for this execution - In the
runmethod, call themainmethod (which is later overwritten by an ETL script).- When it finished, gather a certain number of metrics.
- On failure, logs and raises.
- At the end, observe the execution time.
Then, the ETLs themselves are defined in a monorepo. With a common CI/CD, each ETL will be containerized with Docker and executed later. Defining an ETL then became as simple as:
1class ETLExample(DataFramework):
2 def main(self) -> None:
3 # Gather data
4 # Transform
5 # Send to database
6
7if __name__ == "__main__":
8 ETLExample().run()
From here, the framework handles all the boilerplate.
It is worth noticing: there was nothing particularly novel here. This solution is simply combining concepts established years ago - such as frameworks, polymorphism and inheritance - in a smart way, in order to meet business requirements while yet adhering to good engineering practices.
How did it evolve?
After developing a few tools in the framework and around 3 ETLs in this format, management was convinced that this was the way to go. I got the opportunity to lead the continuous development of the Data Framework and we had a few milestones in place.
From the mess that was there before, now there was a mature framework, 90% covered with unit tests, along with format, linting, and type checking. The ETLs themselves also have unit tests in place (not with high coverage though), and are also checked against format, lint, and typing.
The Docker images were later published to an ECR (Elastic Container Registry), orchestrated with Apache Airflow and executed with Fargate.
Conclusive thoughts
The journey was long, however the impact was positively felt across the data team and many others in the company. The whole process is now automatic, logs are accessible and retained, code is tested, deployments are automatic, stateless and (in most cases) idempotent execution.
Because all the ETL code is in a monorepo, it is also easy for developers to reference each other's code. With format, linting, and typing tools, we also achieved an important level of readability, which also sped up development in general. Finally, and because the setup turned out to be way easier than before, people from other teams were also able to collaborate.